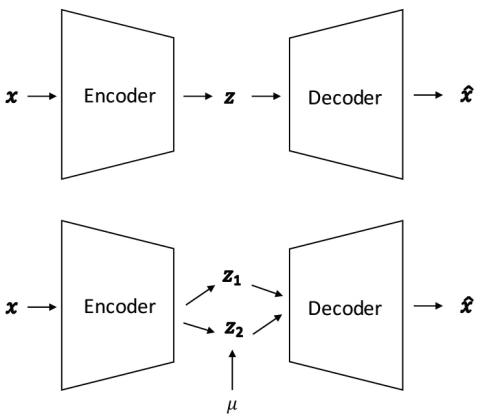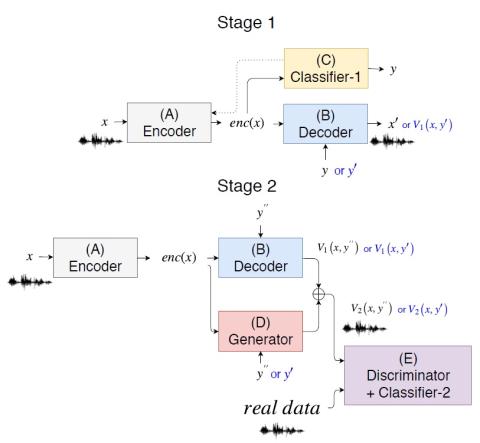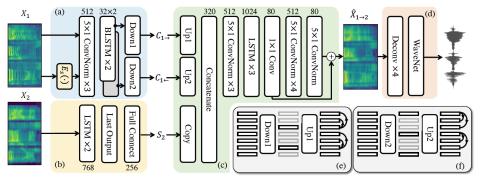
AUTOVC: передача стиля голоса Zero-Shot с потерей только автоэнкодера
Непараллельное преобразование голоса "многие ко многим", а также преобразование голоса с нулевым кадром остаются недостаточно изученными областями. Алгоритмы глубокой передачи стилей, такие как генеративные состязательные сети (GAN) и условно-вариационный автоэнкодер (CVAE), применяются в качестве новых решений в этой области. Однако обучение стрельбе из пистолета является сложным процессом, и нет убедительных доказательств того, что генерируемая им речь обладает хорошим качеством восприятия. С другой стороны, обучение CVAE является простым, но не обладает свойством сопоставления с распределен...