AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss
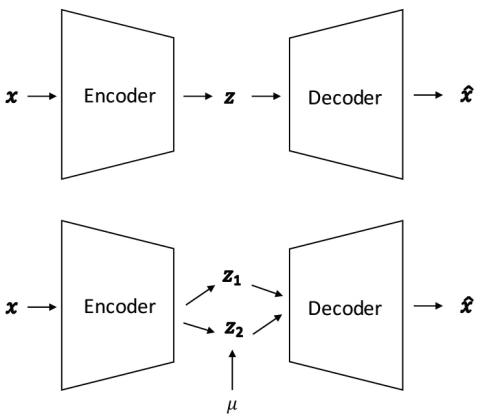
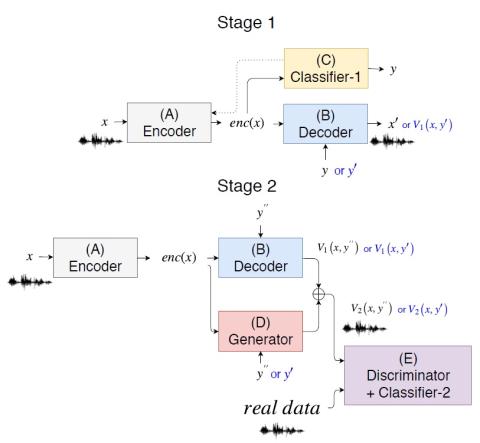
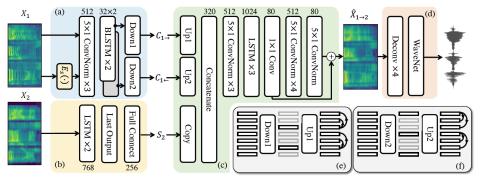
Non-parallel many-to-many voice conversion, as well as zero-shot voice conversion, remain underexplored areas. Deep style transfer algorithms, such as generative adversarial networks (GAN) and conditional variational autoencoder (CVAE), are being applied as new solutions in this field. However, GAN training is sophisticated and difficult, and there is no strong evidence that its generated speech is of good perceptual quality. On the other hand, CVAE training is simple but does not come with the distribution-matching property of a GAN. In this paper, we propose a new style transfer scheme that ...