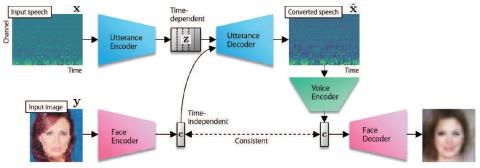
Crossmodal Voice Conversion
Humans are able to imagine a person's voice from the person's appearance and imagine the person's appearance from his/her voice. In this paper, we make the first attempt to develop a method that can convert speech into a voice that matches an input face image and generate a face image that matches the voice of the input speech by leveraging the correlation between faces and voices. We propose a model, consisting of a speech converter, a face encoder/decoder and a voice encoder. We use the latent code of an input face image encoded by the face encoder as the auxiliary input into the speech conv...