This paper evaluates the effectiveness of a Cycle-GAN based voice converter (VC) on four speaker identification (SID) systems and an automated speech recognition (ASR) system for various purposes. Audio samples converted by the VC model are classified by the SID systems as the intended target at up to 46% top-1 accuracy among more than 250 speakers. This encouraging result in imitating the target styles led us to investigate if converted (synthetic) samples can be used to improve ASR training. Unfortunately, adding synthetic data to the ASR training set only marginally improves word and character error rates. Our results indicate that even though VC models can successfully mimic the style of target speakers as measured by SID systems, improving ASR training with synthetic data from VC systems needs further research to establish its efficacy.
Discussion
In this paper, we report that a Cycle-GAN based voice converter model can generate audio files that are classified by four different automated SID models as the intended target speaker at up to 46% top-1 accuracy. There is significant variation among SID models, with deep-learning based models having higher rates of intended target classification than i-vector based models.
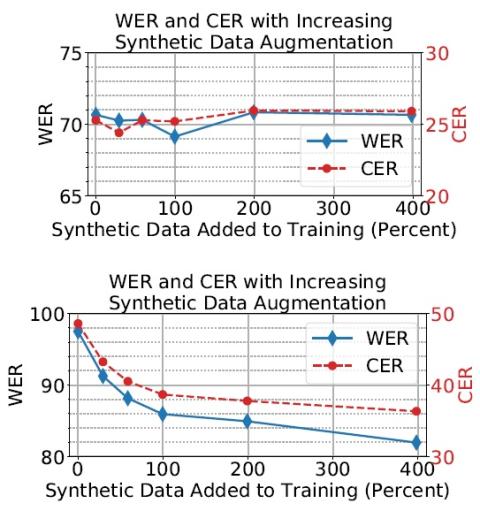
Additionally, we investigate if the high imitation ability of the style, as rated by SID systems, can be used to improve error rates in ASR training. Our results demonstrate marginal improvement in WER/CER rates when the VC model is used to augment ASR training set. This latter result is in line with GAN-based augmentation methods seen in computer vision domain, and demonstrates further research is needed before VC models can be used to aid training in downstream tasks such as ASR. One future direction is to improve VC conversion quality further by using GAN architectures that can mimic styles in finer detail (Karras et al., 2018). Using a neural vocoder to re-build the raw audio waveforms from converted spectrograms to improve the quality of the conversions should also be investigated.