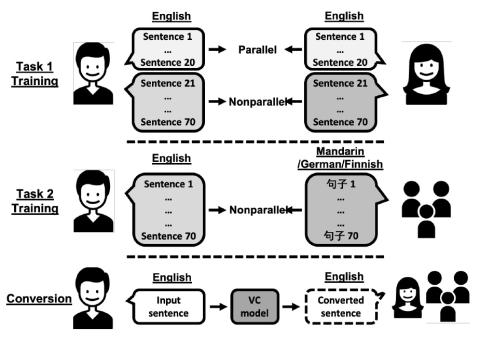
The voice conversion challenge is a bi-annual scientific event held to compare and understand different voice conversion (VC) systems built on a common dataset. In 2020, we organized the third edition of the challenge and constructed and distributed a new database for two tasks, intra-lingual semi-parallel and cross-lingual VC. After a two-month challenge period, we received 33 submissions, including 3 baselines built on the database. From the results of crowd-sourced listening tests, we observed that VC methods have progressed rapidly thanks to advanced deep learning methods. In particular, speaker similarity scores of several systems turned out to be as high as target speakers in the intra-lingual semi-parallel VC task. However, we confirmed that none of them have achieved human-level naturalness yet for the same task. The cross-lingual conversion task is, as expected, a more difficult task, and the overall naturalness and similarity scores were lower than those for the intra-lingual conversion task. However, we observed encouraging results, and the MOS scores of the best systems were higher than 4.0. We also show a few additional analysis results to aid in understanding cross-lingual VC better.
Conclusion
The voice conversion challenge is a bi-annual scientific event held to compare and understand different VC systems built on a common dataset. In 2020, we organized the third edition of the challenge and constructed and distributed a new database for two tasks, intra-lingual semi-parallel and cross-lingual voice conversion. The participants were given two months and two weeks to build VC systems, and we received a total of 33 submissions, including 3 baselines built on the database. From the results of crowd-sourced listening tests, we saw that VC methods have progressed rapidly thanks to advanced deep learning methods. In particular, the speaker similarity scores of several systems turned out to be as high as target speakers in the intra-lingual semi-parallel VC task. However, we confirmed that none of them have achieved human-level naturalness yet for the same task. The cross-lingual conversion task is, as expected, a more difficult task, and the overall naturalness and similarity scores were lower than the intra-lingual conversion task. However, we observed encouraging results, and the MOS scores of the best systems were higher than 4.0.
We also provided a few additional analysis results to aid in understanding cross-lingual voice conversion better. We tried to answer three questions and showed our insights: 1) Do Japanese listeners judge naturalness and speaker similarity in the same way as English subjects? 2) Do subjects judge speaker similarity differently when they listen to reference audio in L2 language? and 3) Is cross-lingual VC performance affected by the language of target speakers? The insights could help us to improve and evaluate cross-lingual voice conversion in the future.