Unsupervised representation learning of speech has been of keen interest in recent years, which is for example evident in the wide interest of the ZeroSpeech challenges. This work presents a new method for learning frame level representations based on WaveNet auto-encoders. Of particular interest in the ZeroSpeech Challenge 2019 were models with discrete latent variable such as the Vector Quantized Variational Auto-Encoder (VQVAE). However these models generate speech with relatively poor quality. In this work we aim to address this with two approaches: first WaveNet is used as the decoder and to generate waveform data directly from the latent representation; second, the low complexity of latent representations is improved with two alternative disentanglement learning methods, namely instance normalization and sliced vector quantization. The method was developed and tested in the context of the recent ZeroSpeech challenge 2020. The system output submitted to the challenge obtained the top position for naturalness (Mean Opinion Score 4.06), top position for intelligibility (Character Error Rate 0.15), and third position for the quality of the representation (ABX test score 12.5). These and further analysis in this paper illustrates that quality of the converted speech and the acoustic units representation can be well balanced.
Conclusions and Future Work
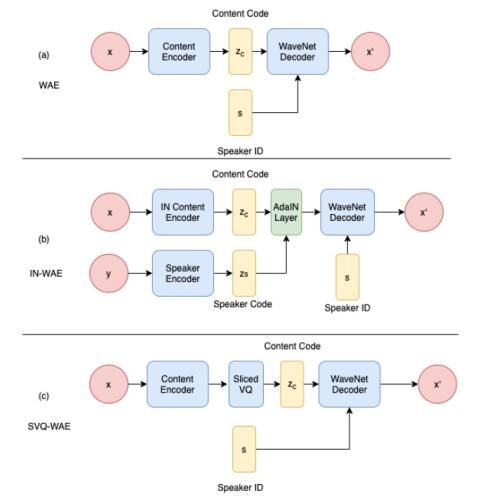
We proposed to incorporate WaveNet auto-encoder with instance normalization and sliced-VQ respectively. In the ZeroSpeech 2020 challenge, the IN-WAE obtains competitive performance on naturalness, intelligibility and representation discriminability. Meanwhile, the SVQ-WAE obtains competitive representation discriminability. In future work, the methods that can achieve good speaker similarity for voice conversion will be explored. Moreover, the techniques that can accelerate the WaveNet auto-encoder model inference will be investigated.