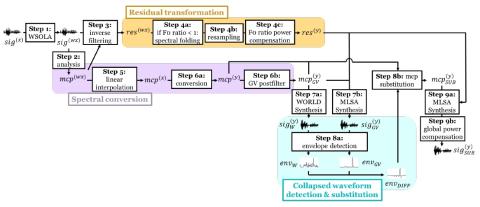
We present a modification to the spectrum differential based direct waveform modification for voice conversion (DIFFVC) so that it can be directly applied as a waveform generation module to voice conversion models. The recently proposed DIFFVC avoids the use of a vocoder, meanwhile preserves rich spectral details hence capable of generating high quality converted voice. To apply the DIFFVC framework, a model that can estimate the spectral differential from the F0 transformed input speech needs to be trained beforehand. This requirement imposes several constraints, including a limitation on the estimation model to parallel training and the need of extra training on each conversion pair, which make DIFFVC inflexible. Based on the above motivations, we propose a new DIFFVC framework based on an F0 transformation in the residual domain. By performing inverse filtering on the input signal followed by synthesis filtering on the F0 transformed residual signal using the converted spectral features directly, the spectral conversion model does not need to be retrained or capable of predicting the spectral differential. We describe several details that need to be taken care of under this modification, and by applying our proposed method to a non-parallel, variational autoencoder (VAE)-based spectral conversion model, we demonstrate that this framework can be generalized to any spectral conversion model, and experimental evaluations show that it can outperform a baseline framework whose waveform generation process is carried out by a vocoder.
Conclusions and Future Work
In this paper, we introduced a generalization of the DIFFVC framework to make it applicable to general VC models. The proposed method is based on an F0 transformation in the residual domain, so that synthesis filtering is performed directly using the converted spectral features, thus removing the need for the conversion model to be able to predict the spectral differential, making the entire process free of parallel training data. We also introduced several techniques used in this framework, including 1) an alternative for high frequency component reconstruction based on zero stuffing, 2) collapsed waveform detection and corresponding feature substitution, and 3) power compensation due to resampling. Experimental results confirmed that when applied to a non-parallel VAE-based VC model, our method outperformed the counterpart that used a conventional vocoder in terms of conversion accuracy, yet the naturalness was on par.
The investigation of the effectiveness of individual components proposed in this work, as well as a more in-depth analysis of the experimental results will be of top prior for future work. We also plan to apply our framework to other non-parallel VC models to further validate the effectiveness. Developing a frequency-wrapping robust spectral feature extractor may help solve the various issues discussed in Section 4.3, which will be another important future work.