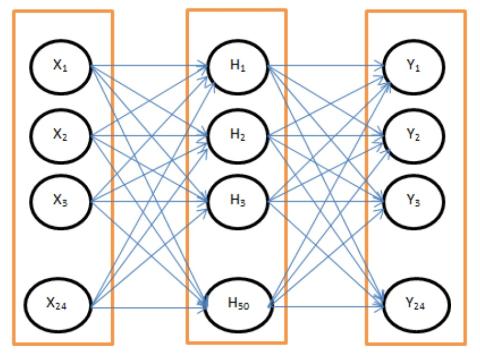
В этом исследовании представлена модель преобразования голоса на основе нейронных сетей. Хотя известно, что озвученные звуки и просодия являются наиболее важными компонентами системы преобразования голоса, неизвестен их объективный вклад, особенно в шумной и неконтролируемой среде. Эта модель использует двухслойную нейронную сеть прямого действия для сопоставления коэффициентов анализа линейного прогнозирования исходного динамика с акустическим векторным пространством целевого говорящего с целью объективного определения вклада озвученных, невокализованных и надсегментарных компонентов звуков в модель преобразования голоса. Результаты показали, что гласные “a”, “i”, “o” вносят наиболее значительный вклад в успешность преобразования. Также было обнаружено, что данные обучения с шумом в наибольшей степени влияют на глухие звуки. Было обнаружено, что средний уровень шума на 40 дБ выше минимального уровня снижает эффективность преобразования голоса на 55,14% по сравнению с озвученными звуками. Результат также показывает, что для преобразования голоса между полами преобразование просодии более важно в сценариях, где целевым носителем является женщина.
Вывод
Эта работа выявила вклад гласных и просодии в основанную на нейронной сети модель преобразования голоса, обученную на зашумленных данных. В большинстве популярных моделей преобразования голоса, описанных в литературе, используются тщательно отобранные обучающие данные, полученные от квалифицированных экспертов по голосоведению, и поэтому вклад просодии и дикции говорящего, особенно в артикуляцию звонких и глухих звуков, был упущен из виду. Это исследование показало, что для моделей преобразования голоса, обученных на образцах, записанных в неконтролируемой шумной среде, более важную роль играют невокализованные звуки, которые в основном согласные. Исследование также показало, что в подобных ситуациях преобразование просодии еще более важно для преобразования мужского пола в женский. Дальнейшая работа будет включать изучение процентного соотношения всех известных озвученных и невокализованных звуков в английском языке, поскольку это будет полезно в ситуациях, когда доступно или допустимо для целей обучения очень мало данных об обучении.