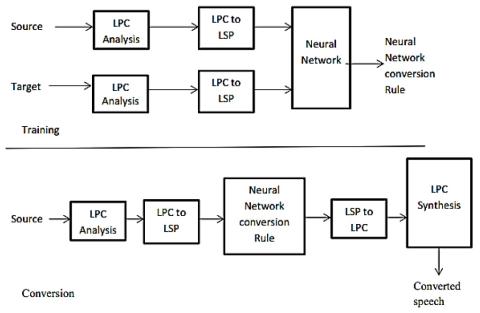
В исследовании представлена модель преобразования голоса с использованием отображения коэффициентов и нейронной сети. В большинстве предыдущих работ по параметрическому синтезу речи не учитывались потери в спектральных деталях, что приводило к чрезмерному сглаживанию и, как правило, к заметному отклонению преобразованной речи от целевой. В этой работе была разработана усовершенствованная модель, которая использует как коэффициенты линейного кодирования с предсказанием (LPC), так и коэффициенты линейной спектральной частоты (LSF) для параметризации исходного речевого сигнала, чтобы выявить эффект чрезмерного сглаживания. Способность нейронной сети к нелинейному отображению была использована для отображения речевых векторов источника в акустическое векторное пространство объекта. Обучение коэффициентов LPC с помощью нейронной сети дало плохой результат из-за нестабильности полюсов фильтра LPC. Коэффициенты LPC были преобразованы в линейчатые спектрально-частотные коэффициенты перед обучением с помощью 3-слойной нейронной сети. Алгоритм был протестирован на данных с зашумленными данными, а результат был оценен с помощью мелкосепстрального измерения расстояния. Оценка спектрального расстояния показывает уменьшение спектрального расстояния между объектом и преобразованным голосом на 35,7%.
Вывод
В этой работе используются коэффициенты фильтрации LPC и LSF, чтобы подчеркнуть влияние параметризации речи на преобразование голоса. Потери в спектральных характеристиках приводят к чрезмерному сглаживанию, что влияет на качество синтезированной речи с точки зрения расстояния между объектом и преобразованным голосом. Для выполнения преобразования голоса была использована нейронная сеть и LSF, и результат показывает улучшение в рамках существующей модели.