We present the Voice Conversion Challenge 2018, designed as a follow up to the 2016 edition with the aim of providing a common framework for evaluating and comparing different state-of-the-art voice conversion (VC) systems. The objective of the challenge was to perform speaker conversion (i.e. transform the vocal identity) of a source speaker to a target speaker while maintaining linguistic information. As an update to the previous challenge, we considered both parallel and non-parallel data to form the Hub and Spoke tasks, respectively. A total of 23 teams from around the world submitted their systems, 11 of them additionally participated in the optional Spoke task. A large-scale crowdsourced perceptual evaluation was then carried out to rate the submitted converted speech in terms of naturalness and similarity to the target speaker identity. In this paper, we present a brief summary of the state-of-the-art techniques for VC, followed by a detailed explanation of the challenge tasks and the results that were obtained.
Conclusion
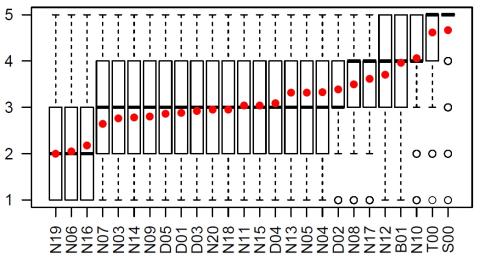
This paper presented the second edition of the Voice Conversion Challenge (VCC 2018), which has continued the trend of providing a common framework for the development and evaluation of voice conversion systems. In this challenge, we have seen the incredible progress that has come to the field with the rise of new speech generation paradigms such as Wavenet, showing performances that produce converted speech with a quality similar to that of natural speech. From the listening test, we observed that one of the submitted VC systems achieved remarkable results. This system obtained an average of 4.1 in the five-point scale evaluation for quality judgment and about 80% of its converted speech samples were judged to be the same as target speakers by listeners. We see the results of the VCC 2018 as a potential paradigm shift in the field to convince teams all over the world to consider these new approaches. All the training and evaluation data released to participants, submissions from participants, and the listening test results are publicly and permanently available at the Edinburgh datashare.