We have previously proposed a method that allows for non-parallel voice conversion (VC) by using a variant of generative adversarial networks (GANs) called StarGAN. The main features of our method, called StarGAN-VC, are as follows: First, it requires no parallel utterances, transcriptions, or time alignment procedures for speech generator training. Second, it can simultaneously learn mappings across multiple domains using a single generator network so that it can fully exploit available training data collected from multiple domains to capture latent features that are common to all the domains. Third, it is able to generate converted speech signals quickly enough to allow real-time implementations and requires only several minutes of training examples to generate reasonably realistic-sounding speech. In this paper, we describe three formulations of StarGAN, including a newly introduced novel StarGAN variant called "Augmented classifier StarGAN (A-StarGAN)", and compare them in a non-parallel VC task. We also compare them with several baseline methods.
Conclusions
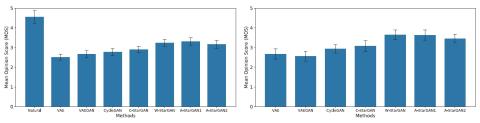
In this paper, we proposed a method that allows non-parallel multi-domain VC based on StarGAN. We described three formulations of StarGAN and compared them and several baseline methods in a non-parallel speaker identity conversion task. Through objective evaluations, we confirmed that our method was able to convert speaker identities reasonably well using only several minutes of training examples. Interested readers are referred to [87], [88] for our investigations of other network architecture designs and improved techniques for CycleGAN-VC and StarGAN-VC.
One limitation of the proposed method is that it can only convert input speech to the voice of a speaker seen in a given training set. It owes to the fact that one-hot encoding (or a simple embedding) used for speaker conditioning is nongeneralizable to unseen speakers. An interesting topic for future work includes developing a zero-shot VC system that can convert input speech to the voice of an unseen speaker by looking at only a few of his/her utterances. As in the recent work [89], one possible way to achieve this involves using a speaker embedding pretrained based on a metric learning framework for speaker conditioning.