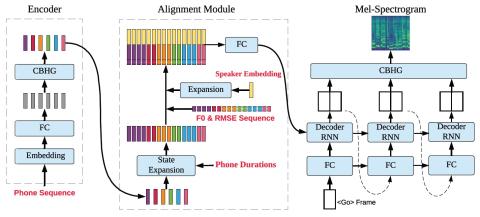
Singing voice conversion is converting the timbre in the source singing to the target speaker's voice while keeping singing content the same. However, singing data for target speaker is much more difficult to collect compared with normal speech data.In this paper, we introduce a singing voice conversion algorithm that is capable of generating high quality target speaker's singing using only his/her normal speech data. First, we manage to integrate the training and conversion process of speech and singing into one framework by unifying the features used in standard speech synthesis system and singing synthesis system. In this way, normal speech data can also contribute to singing voice conversion training, making the singing voice conversion system more robust especially when the singing database is small.Moreover, in order to achieve one-shot singing voice conversion, a speaker embedding module is developed using both speech and singing data, which provides target speaker identify information during conversion. Experiments indicate proposed sing conversion system can convert source singing to target speaker's high-quality singing with only 20 seconds of target speaker's enrollment speech data.
Conclusion
In this paper, we proposed an singing voice conversion model DurIAN-SC with a unified framework of speech and singing data. For those speakers with none singing data, our method could convert to their singings by training on only their speech data. Through a pre-trained speaker embedding network, we could convert to ’unseen’ speakers’ singing with only a 20 second length of data. Experiments indicate the proposed model can generate high-quality singing voices for in-set ’seen’ target speakers in terms of both naturalness and similarity. In the meanwhile, proposed system can also one-shot convert to out-of-set ’unseen’ users with small register data. In the future work, we will continue to make our model nore robust and improve the similarity of the ’unseen’ singing voice conversion.