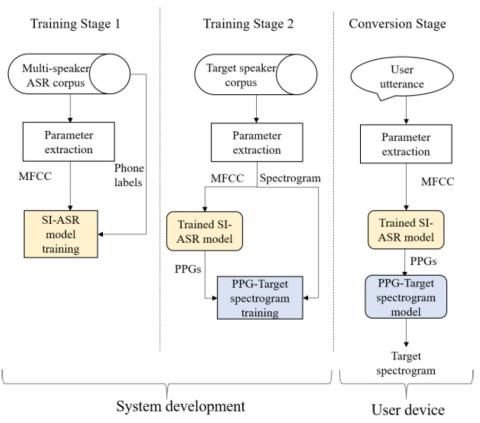
Recent works of utilizing phonetic posteriograms (PPGs) for non-parallel voice conversion have significantly increased the usability of voice conversion since the source and target DBs are no longer required for matching contents. In this approach, the PPGs are used as the linguistic bridge between source and target speaker features. However, this PPG-based non-parallel voice conversion has some limitation that it needs two cascading networks at conversion time, making it less suitable for real-time applications and vulnerable to source speaker intelligibility at conversion stage. To address this limitation, we propose a new non-parallel voice conversion technique that employs a single neural network for direct source-to-target voice parameter mapping. With this single network structure, the proposed approach can reduce both conversion time and number of network parameters, which can be especially important factors in embedded or real-time environments. Additionally, it improves the quality of voice conversion by skipping the phone recognizer at conversion stage. It can effectively prevent possible loss of phonetic information the PPG-based indirect method suffers. Experiments show that our approach reduces number of network parameters and conversion time by 41.9% and 44.5%, respectively, with improved voice similarity over the original PPG-based method.
Conclusions
In this paper, we propose a new non-parallel voice conversion approach that employs a single network for source-to-target feature mapping without the use of PPGs at conversion stage. Due to this straightforward architecture, our method runs faster and requires smaller amount of memory. It also improved the MCD by eliminating the information loss resulted from the PPG-based linguistic bridge. It is confirmed in experiments that the proposed method reduces the conversion time by 44.5 % and the amount of network parameters by 41.9 % with maximum 4.8 % MCD improvement compared to the baseline.
This reduction in conversion time by the proposed method can be further achieved when deployed in combination with network models of smaller size and fewer parameters.
As further work, it will be interesting to conduct performance comparison between the proposed approach and the parallel voice conversion method.