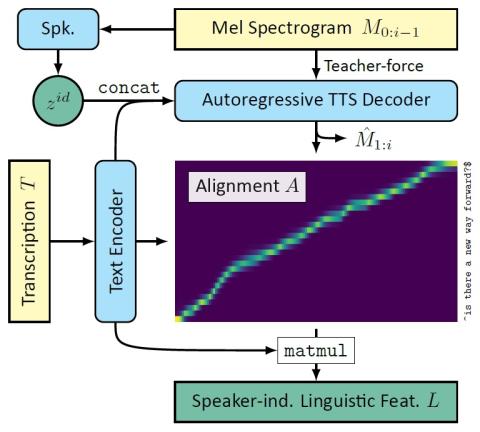
We propose Cotatron, a transcription-guided speech encoder for speaker-independent linguistic representation. Cotatron is based on the multispeaker TTS architecture and can be trained with conventional TTS datasets. We train a voice conversion system to reconstruct speech with Cotatron features, which is similar to the previous methods based on Phonetic Posteriorgram (PPG). By training and evaluating our system with 108 speakers from the VCTK dataset, we outperform the previous method in terms of both naturalness and speaker similarity. Our system can also convert speech from speakers that are unseen during training, and utilize ASR to automate the transcription with minimal reduction of the performance. Audio samples are available at https://mindslab-ai.github.io/cotatron, and the code with a pre-trained model will be made available soon.
Discussion
In this paper, we proposed Cotatron, a transcription-guided speech encoder for speaker-independent linguistic representation, which is based on the multispeaker Tacotron2 architecture. Our Cotatron-based voice conversion system reaches state-of-the-art performance in terms of both naturalness and speaker similarity on conversion across 108 speakers from the VCTK dataset and shows promising results on conversion from arbitrary speakers. Even when the automated transcription with errors is fed, the performances remained the same.
To our best knowledge, Cotatron is the first model to encode speaker-independent linguistic representation by explicitly aligning the transcription with given speech. This could open a new path towards multi-modal approaches for speech processing tasks, where only the speech modality was usually being used. For example, one may consider training a transcription-guided speech enhancement system based on Cotatron features. Furthermore, traditional speech features that were utilized for lip motion synthesis can be possibly replaced with Cotatron features to incorporate the transcription for better quality.
Still, there is plenty of room for improvement in the voice conversion system with Cotatron. Despite our careful design choices, the residual encoder seems to provide speech features that are entangled with speaker identity, which may harm the conversion quality or even cause mispronunciation issues. Besides, methods for conditioning the target speaker’s representation could be possibly changed; e.g., utilizing a pre-trained speaker verification network as a speaker encoder may enable any-to-any conversion with our system.